Herramientas/Tool Index
Building Detection

This is a machine learning model that uses high resolution satellite images as an input to analyze and identify existing buildings in cities.
The general objective of the model is to support leaders in the urban development and housing sector to generate, automatically, basic maps of existing buildings in urban areas and human settlements.
Inter-American Development Bank
USE CASES:
This type of classification of structures is useful for urban planning tasks such as the identification and planning of informal / unplanned zones, the design and development of urban services, and to extrapolate data at the city level such as the number of buildings and population estimates.
To train the model, high-resolution images of the IDB's Emerging and Sustainable Cities Program were used from the following cities:
- Georgetown, Guyana
- Paramaribo, Suriname
- Belize, Belize
FUNCTIONS:
- Analyze imagery.
- Training a model for three Latin American cities, this automation reduces the time required to one day instead of one month (manual).
- Produce a prediction package which can be used to make predictions on new imagery
This model of real estate segmentation allows to predict raster masks and vectorized polygons of satellite images using a semantic segmentation approach.
This process assigns a category to each pixel of the image. In this case, the categories used are 'real estate' or 'non-real property'. By allowing a segmentation that recognizes the unique characteristics of each city (different urbanization patterns, different geographical features, etc.), this tool is applicable in several contexts.
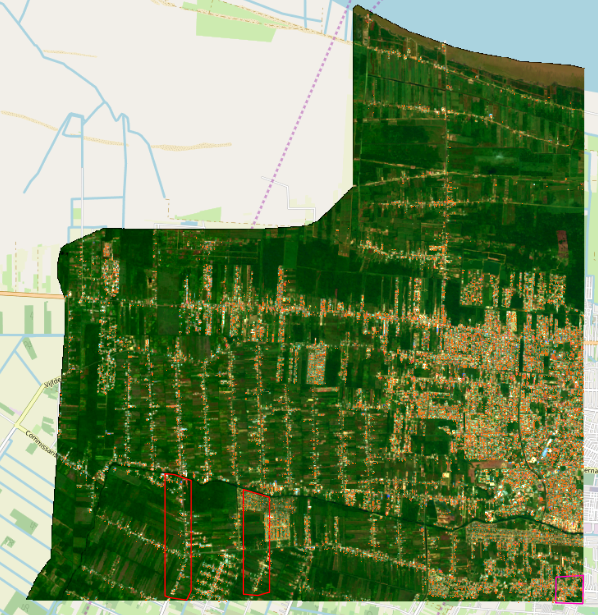
This image presents results for Paramaribo. The orange color shows the buildings identified by the model. It took approximately eight hours to perform the manual identification of structures in the dark pink polygon, located in the lower right corner. The model manages to make the identification of the entire city in just one hour, using as training data labels generated through crowd-sourcing in Openstreetmap for the area in the red polygons.